Emba — An analyzer for embedded Linux firmware

This article is no longer up-to-date due to the rapid development at EMBA. Nevertheless, it is definitely worth reading and can help with a basic understanding of the tool. If you are interested in the new features, then I can only recommend trying out the tool and reading the documentation.
There are many modern “Internet of Things” (IoT) devices that are no longer based solely on bare metal programming. Many of these devices today contain a full operating system, such as Linux. In the current situation, you probably spend more time at home than usual. Just have a look at all the devices in your immediate area, you will surely see at least one smart device that includes a full operating system, maybe even one that is Linux-based. From a small Amazon Echo, to a Philips Hue set, to your smart TV, internet router or even your fridge, these smart devices are everywhere.
Nowadays there are more than 30 billion IoT devices and they are not only found in our homes but also in commercial settings worldwide. From the technology that controls a manufacturing processing plan to the robots that operate in large warehouses, this technology communicates via the internet. This technological trend shows exponential growth, and we can even expect more than 75 billion IoT devices to be used in 2025, which is three times more than the number of loT devices that were used in 2020. [1]
Linux is often the first choice for operating system in all kinds of devices, based on its various features and known environment. One of the main selling points for Linux is its capability to support many different features, but this is also a critical flaw. However, despite this, many vendors still use Linux as the OS for their devices and the statistics share a similar story; In a survey conducted by Eclipse IoT Working Group, AGILE IoT, IEEE, and the Open Mobile Alliance in 2018, over 70% of people preferred using Linux as the most favorable OS for an IoT device. [2]

With so many devices today, that use Linux as the main OS and with a growing number of devices that will use Linux in the future, many vendors are modifying it to fit their needs. However, without verification, these changes can cause a numerous amount of new security gaps to arise.
But how is it possible to find vulnerabilities in this bloated firmware?
Emba — an analyzer for Linux-based firmware of embedded devices

Emba is being developed as a firmware scanner that analyzes Linux-based firmware images, regardless of whether it is a single file or has already been extracted. It will support you in identifying and focusing on interesting areas of these images.
Emba is optimized for offline firmware images, it can test both, extracted firmware filesystems and firmware files. Additionally, it can also analyze kernel configurations. Emba will assist the tester by providing as much information as possible about the firmware. The tester can then decide on focus areas and verify and interpret the results.
There is a broad variety of software available that can analyze Linux firmware, however none of them could fulfill our expectations. Therefore, we combined the best tools into one simple application. The focus of emba is to be easy to use, easy to customize and to find and display all possible weak points. In the beginning of this project, we decided that emba should be able to run with only two parameters: path to your firmware (as binary or already extracted) and path to a directory for the generated log files. Emba won’t take hours to learn how to use and it will improve your workflow. During the development, we added many new features without compromising the simplicity. This is also why we use bash and have no plans to rewrite emba in another language.
How emba is structured
In the main directory, there is the main script of emba emba.sh, the installer script installer.sh and some other files that are needed in order to run and develop emba. In the main script emba.sh, emba checks for all given parameters and loads all helper and module files. The helper files contain functionalities, such as the creation of the log file, but the main areas of focus are the modules themselves. They are sorted via a simple schematic in their name:
- P… are pre-modules
These will be loaded and called before everything else, but only if the provided firmware is a file. Their primary task is to extract firmware out of binaries, detect the root directory and detect the operating system of the firmware. If the firmware is already extracted, emba will skip these modules.
- S… are standard modules for testing Linux
These are the core modules of emba. Here you will find all checks for possible vulnerabilities.
- R… are standard modules for testing non-Linux
These are also core modules, but only for firmware that isn’t Linux
- F… are finishing modules
These modules are the last ones in an emba run. They are used for summarizing and presenting an overview of the results of the previous modules.
The numbers after the grouping letter are for the order of execution, e.g. S20… will be executed after S15….
Additionally, there is a configuration directory, that contains multiple data files for the modules. If a module needs, for example a list of filenames, then it will access the data from the configuration directory. This helps keep the modules clean and organized.
Modules
Presently, emba contains over 35 different modules with a variety of different features. It’s very difficult to summarize all the features of emba, simply because there are too many of them and they are sometimes very different from each other. In order to get an overview of the modules and the external tools used, please check out the detailed documentation of emba on our project page.
If you start emba with a firmware file that isn’t already extracted, then it will analyze it, check the entropy, and if possible, extract the firmware in the logging directory for further analysis. The entropy of a firmware shows if it is encrypted and/or compressed. In the next step, emba will identify the operating system and if the OS is Linux, then emba will iterate through all the files and look for version numbers.
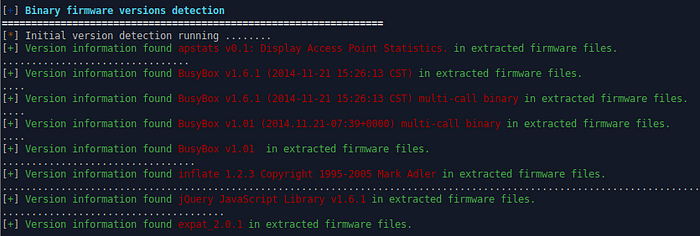
The version numbers combined with the name of the application make it possible to look for known vulnerabilities. If the OS is not Linux, then the application runs the R modules instead of the S modules after the static analysis of the firmware file. In the next part only the S modules will be described because that’s the main focus of emba.
The first core modules give you basic information about the firmware, such as the file, the executable count and the content from known release files, then they continue to check all binaries for weak functions and protection mechanisms.
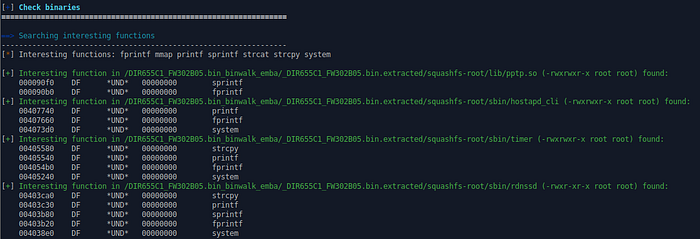
For example, strcpy is one of the functions that emba checks. This function, as the name already suggests, copies a String (Text) from one place to another and if that String is too big to be copied, then it could crash the firmware. After parsing for possible information about the bootloader and the system startup, it checks shell scripts, Python and PHP files for bugs, stylistic errors, etc., in order to find files that were written by the vendor of the firmware. Linux distributions are highly maintained and have already been meticulously checked, therefore it’s essential to identify the programs that have been added later by the vendor.

The system startup is interesting because every system begins with full permissions on everything and then step by step these permissions are degraded. The more permissions a system has, then the more attractive it is to attack that system.
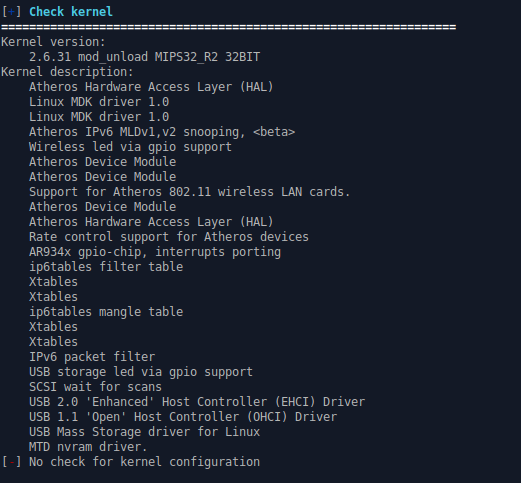
The next two modules determine kernel versions and configurations. It then iterates through all binaries searching for possible version numbers in order to lookup their occurrences in the CVE (Common Vulnerabilities and Exposures) database. The kernel version will also be checked for known vulnerabilities and all kernel modules will be analyzed for their license and whether or not the license is proprietary. If the module is not stripped and proprietary (shows debug information), then it will be marked. The kernel in most firmware is often not updated, and as the core of the firmware, if it is not updated then it is highly vulnerable.
After that, emba checks many different files. It starts with http and webserver files from Apache, nginx, etc. and continues to scan for setuid, setgid, world writable and shadow files as well as the permissions of rc.d and init.d. If the permissions are wrong, then that is often an indicator that the vendor of the firmware changed something and is always a good spot to look for open gateways. Many attacks on systems happen over their running webservers because this is often the only spot that is addressable from the network.
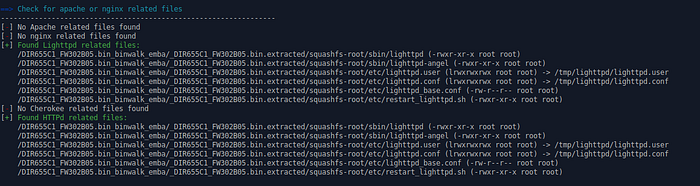
Emba will also look for all password files and if found, emba will extract them with their account’s information. Emba will also check for users with an UID of zero (in most cases root account), in addition to checking for other user accounts, groups and their authentication. If the root account with its password is exposed, then the firmware is not secure and shouldn’t be used at all.
In the following modules, emba will look for history files, like .bash_history and iterate through the filesystem in order to search for certification files. Certificates always have a start and end date and if the end date is in the future, then these certifications could be exploited by an attacker.
Some information can often be found hidden in the configuration and network files. These areas will also be checked by emba and if hidden files are found, then they will be shown, and the user can decide if they are interesting enough to research further.
In one of the previous modules, there was a check for the system startup and in addition to that emba will search through all cronjob files. If you know that an application will automatically start during the system startup, then you can focus your attention on that application. The next modules are again file checks but this time emba will check for mail files on the system, ssh files (and further checks on the configuration files planned) and for interesting binaries. Some binaries are often more vulnerable than others, because they use, for example, a port like ssh (port 22) or telnet (port 23) and are reachable via the network. In order to find more injection points, emba searches for files and directories that are used by web scripts and then lists them for manual investigation.
The next two modules are deep search modules. Due to this, they take more time to run, since all the files in your firmware will be checked against a dictionary and if the same word is found, then it will be shown. In these dictionaries, there are words like password or a pattern of private keys. The latter is particularly interesting because a private key can be used for authentication without a password.


In emba there is also a large dictionary of all standard files of ordinary Linux images, such as Debian. If there are files that have never been in a newly installed distribution, then they are likely from the vendor changing the firmware.


The last modules of the core part of emba are the interesting because emba emulates all executables from the firmware with qemu in order to find version numbers and to search for the CVEs of these applications. In the final modules, emba will give you an overview of all found CVEs and detailed information on exploitable vulnerabilities that were found. Before the summary module begins, emba also searches through all binaries for known CWEs (Common Weakness Enumeration). In the CVE databases there are specific instances of a product or system listed but the underlying flaw is not shown. In contrast, the CWE database focuses on the flaws and not on the product.

As already discussed, the finishing modules will aggregate all found version numbers, search for known CVEs and then summarize all interesting findings.
How to use emba
If you’ve got your hands on a firmware image and a Linux machine with some disk space, then that is basically everything you need in order to use emba. But not so fast, first you must install some software for emba. The details for this process can be found on the project page.
In short, there are two different modes, that emba can be used on. The first mode is the classical mode, where all dependencies for emba will be installed on the host. The second mode is to use emba with Docker. For that you only have to install Docker on your system and then run emba. It will automatically use the right container and install all necessary applications.
Is everything installed on your system? Alright, now start emba with the right parameters, at least the path to the firmware and to a directory in order to write all the log files. We want the entry barrier as low as possible, so that emba can check as many things as possible for you and improve your workflow. For experienced users, emba has a range of arguments to start additional modules, change output/log, turn on the web report and so on.
Outlook
The next steps with emba are mostly improvement, such as fixing bugs and testing. We need to test a huge amount of different firmware in order to find abnormalities and to implement a detection for these. We have already tested some huge firmware images and unfortunately noticed that these images take many days to analyze and we are currently working on improving the speed. We are also looking for people who are willing to test their firmware in order to help and improve emba. This is one of the reasons why we switched emba to an open source, so that it can be used and improved by everybody. It has now been over six months on github.com and emba seems very popular. We will continue to improve emba in order to make it even better.
Interested in emba? Subscribe to the repository on github and don’t miss new features.
[1][https://www.statista.com/statistics/471264/iot-number-of-connected-devices-worldwide]
[2][https://www.itprotoday.com/iot/survey-shows-linux-top-operating-system-internet-things-devices]
